tl;dr If we started a new domain-specific language tomorrow, we could choose between different language workbenches or, more general, textual vs. structural / projectional systems. We should decide case-by-case, guided by the criteria targeted user group, tool environment, language properties, input type, environment, model-to-model and model-to-text transformations, extensibility, theory, model evolution, language test support, and longevity.
Continue reading
Xtext vs. MPS: Decision Criteria
MPS’ Quest of the Holy GraalVM of Interpreters
A vision how to combine MPS and GraalVM
Way too long ago, I prototyped a way to use GraalVM and Truffle inside JetBrains MPS. I hope to pick up this work soon. In this article, I describe the grand picture of what might be possible with this combination.
Part I: Get it Working
Step 0: Teach Annotation Processors to MPS
Truffle uses Java Annotation Processors heavily. Unfortunately, MPS doesn’t support them during its internal Java compilation. The feature request doesn’t show any activity.
So, we have to do it ourselves. A little less time ago, I started with an alternative Java Facet to include Annotation Processors. I just pushed my work-in-progress state from 2018. As far as I remember, there were no fundamental problems with the approach.
Optional Step 1: Teach Truffle Structured Sources
For Truffle, all executed programs stem from a Source. However, this Source can only provide Bytes or Characters. In our case, we want to provide the input model. The prototype just put the Node id of the input model as a String into the Source; later steps resolved the id against MPS API. This approach works and is acceptable; directly passing the input node as object would be much nicer.
Step 2: Implement Truffle Annotations as MPS Language
We have to provide all additional hints as Annotations to Truffle. They are complex enough, so we want to leverage MPS’ language features to directly represent all Truffle concepts.
This might be a simple one-to-one representation of Java Annotations as MPS Concepts, but I’d guess we can add some more semantics and checks. Such feedback within MPS should simplify the next steps: Annotation Processors (and thus, Truffle) have only limited options to report issues back to us.
We use this MPS language to implement the interpreter for our DSL. This results in a TruffleLanguage for our DSL.
Step 3: Start Truffle within MPS
At the time when I wrote the proof-of-concept, a TruffleLanguage had to be loaded at JVM startup. To my understanding, Truffle overcame this limitation. I haven’t looked into the current possibilities in detail yet.
I can imagine two ways to provide our DSL interpreter to the Truffle runtime:
- Always register MpsTruffleLanguage1, MpsTruffleLanguage2, etc. as placeholders. This would also work at JVM startup. If required, we can register additional placeholders with one JVM restart.
All non-colliding DSL interpreters would be MpsTruffleLanguage1 from Truffle’s point of view. This works, as we know the MPS language for each input model, and can make sure Truffle uses the right evaluation for the node at hand. We might suffer a performance loss, as Truffle had to manage more evaluations.What are non-colliding interpreters? Assume we have a state machine DSL, an expression DSL, and a test DSL. The expression DSL is used within the state machines; we provide an interpreter for both of them.
We provide two interpreters for the test DSL: One executes the test and checks the assertions, the other one only marks model nodes that are covered by the test.
The state machine interpreter, the expression interpreter, and the first test interpreter are non-colliding, as they never want to execute on the same model node. All of them go to MpsTruffleLanguage1.
The second test interpreter does collide, as it wants to do something with a node also covered by the other interpreters. We put it to MpsTruffleLanguage2. - We register every DSL interpreter as a separate TruffleLanguage. Nice and clean one-to-one relation. In this scenario, we probably had to get Truffle Language Interop right. I have not yet investigated this topic.
Step 4: Translate Input Model to Truffle Nodes
A lot of Truffle’s magic stems from its AST representation. Thus, we need to translate our input model (a.k.a. DSL instance, a.k.a. program to execute) from MPS nodes into Truffle Nodes.
Ideally, the Truffle AST would dynamically adopt any changes of the input model — like hot code replacement in a debugger, except we don’t want to stop the running program. From Truffle’s point of view this shouldn’t be a problem: It rewrites the AST all the time anyway.
DclareForMPS seems a fitting technology. We define mapping rules from MPS node to Truffle Node. Dclare makes sure they are in sync, and input changes are propagated optimally. These rules could either be generic, or be generated from the interpreter definition.
We need to take care that Dclare doesn’t try to adapt the MPS nodes to Truffle’s optimizing AST changes (no back-propagation).
We require special handling for edge cases of MPS → Truffle change propagation, e.g. the user deletes the currently executed part of the program.
For memory optimization, we might translate only the entry nodes of our input model immediately. Instead of the actual child Truffle Nodes, we’d add special nodes that translate the next part of the AST.
Unloading the not required parts might be an issue. Also, on-demand processing seems to conflict with Dclare’s rule-based approach.
Part II: Adapt to MPS
Step 5: Re-create Interpreter Language
The MPS interpreter framework removes even more boilerplate from writing interpreters than Truffle. The same language concepts should be built again, as abstraction on top of the Truffle Annotation DSL. This would be a new language aspect.
Step 6: Migrate MPS Interpreter Framework
Once we had the Truffle-based interpreter language, we want to use it! Also, we don’t want to rewrite all our nice interpreters.
I think it’s feasible to automatically migrate at least large parts of the existing MPS interpreter framework to the new language. I would expect some manual adjustment, though. That’s the price we had to pay for two orders of magnitude performance improvement.
Step 7: Provide Plumbing for BaseLanguage, Checking Rules, Editors, and Tests
Using the interpreter should be as easy as possible. Thus, we have to provide the appropriate utilities:
- Call the interpreter from any BaseLanguage code.
We had to make sure we get language / model loading and dependencies right. This should be easier with Truffle than with the current interpreter, as most language dependencies are only required at interpreter build time. - Report interpreter results in Checking Rules.
Creating warnings or errors based on the interpreter’s results is a standard use-case, and should be supported by dedicated language constructs. - Show interpreter results in an editor.
As another standard use-case, we might want to show the interpreter’s results (or a derivative) inside an MPS editor. Especially for long-running or asynchronous calculations, getting this right is tricky. Dedicated editor extensions should take care of the details. - Run tests that involve the interpreter.
Yet another standard use-case: our DSL defines both calculation rules and examples. We want to assure they are in sync, meaning executing the rules in our DSL interpreter and comparing the results with the examples. This must work both inside MPS, and in a headless build / CI test environment.
Step 8: Support Asynchronous Interpretation and/or Caching
The simple implementation of interpreter support accepts a language, parameters, and a program (a.k.a. input model), and blocks until the interpretation is complete.
This working mode is useful in various situations. However, we might want to run long-running interpretations in the background, and notify a callback once the computation is finished.
Example: An MPS editor uses an interpreter to color a rule red if it is not in accordance with a provided example. This interpretation result is very useful, even if it takes several seconds to calculate. However, we don’t want to block the editor (or even whole MPS) for that long.
Extending the example, we might also want to show an error on such a rule. The typesystem runs asynchronously anyways, so blocking is not an issue. However, we now run the same expensive interpretation twice. The interpreter support should provide configurable caching mechanisms to avoid such waste.
Both asynchronous interpretation and caching benefit from proper language extensions.
Step 9: Integrate with MPS Typesystem and Scoping
Truffle needs to know about our DSL’s types, e.g. for resolving overloaded functions or type casting. We already provide this information to the MPS typesystem. I didn’t look into the details yet; I’d expect we could generate at least part of the Truffle input from MPS’ type aspect.
Truffle requires scoping knowledge to store variables in the right stack frame (and possibly other things I don’t understand yet). I’d expect we could use the resolved references in our model as input to Truffle. I’m less optimistic to re-use MPS’ actual scoping system.
For both aspects, we can amend the missing information in the Interpreter Language, similar to the existing one.
Step 10: Support Interpreter Development
As DSL developers, we want to make sure we implemented our interpreter correctly. Thus, we write tests; they are similar to other tests involving the interpreter.
However, if they fail, we don’t want to debug the program expressed in our DSL, but our interpreter. For example, we might implement the interpreter for a switch-like construct, and had forgotten to handle an implicit default case.
Using a regular Java debugger (attached to our running MPS instance) has only limited use, as we had to debug through the highly optimized Truffle code. We cannot use Truffle’s debugging capabilities, as they work on the DSL.
There might be ways to attach a regular Java debugger running inside MPS in a different thread to its own JVM. Combining the direct debugger access with our knowledge of the interpreter’s structure, we might be able to provide sensible stepping through the interpreter to the DSL developer.
Simpler ways to support the developers might be providing traces through the interpreter, or ship test support where the DSL developer can assure specific evaluators were (not) executed.
Step 11: Create Language for Interop
Truffle provides a framework to describe any runtime in-memory data structure as Shape, and to convert them between languages. This should be a nice extension of MPS’ multi-language support into the runtime space, supported by an appropriate Meta-DSL (a.k.a. language aspect).
Part III: Leverage Programming Language Tooling
Step 12: Connect Truffle to MPS’ Debugger
MPS contains the standard interactive debugger inherited from IntelliJ platform.
Truffle exposes a standard interface for interactive debuggers of the interpreted input. It takes care of the heavy lifting from Truffle AST to MPS input node.
If we ran Truffle in a different thread than the MPS debugger, we should manage to connect both parts.
Step 13: Integrate Instrumentation
Truffle also exposes an instrumentation interface. We could provide standard instrumentation applications like “code” coverage (in our case: DSL node coverage) and tracing out-of-the-box.
One might think of nice visualizations:
- Color node background based on coverage
- Mark the currently executed part of the model
- Project runtime values inline
- Show traces in trace explorer
Other possible applications:
- Snapshot mechanism for current interpreter state
- Provide traces for offline debugging, and play them back
Part IV: Beyond MPS
Step 14: Serialize Truffle Nodes
If we could serialize Truffle Nodes (before any run-time optimization), we would have an MPS-independent representation of the executable DSL. Depending on the serialization format (implement Serializable, custom binary format, JSON, etc.), we could optimize for use-case, size, loading time, or other priorities.
Step 15: Execute DSL stand-alone without Generator
Assume an insurance calculation DSL.
Usually, we would implement
- an interpreter to execute test cases within MPS,
- a Generator to C to execute on the production server,
- and a Generator to Java to provide an preview for the insurance agent.
With serialized Truffle Nodes, we need only one interpreter:
- It runs out-of-the-box in MPS,
- Works stand-alone through GraalVM’s ahead-of-time compiler Substrate VM,
- and can be used on any JVM using Truffle runtime.
Part V: Crazy Ideas
Step 16: Step Back Debugger
By combining Instrumentation and debugger, it might be feasible to provide step-back debugging.
In the interpreter, we know the complete global state of the program, and can store deltas (to reduce memory usage). For quite some DSLs, this might be sufficient to store every intermediate state and thus arbitrary debug movement.
Step 17: Side Step Debugger
By stepping back through our execution and following different execution paths, we could explore alternate outcomes. The different execution path might stem from other input values, or hot code replacement.
Step 18: Explorative Simulations
If we had a side step debugger, nice support to project interpretation results, and a really fast interpreter, we could run explorative simulations on lots of different executions paths. This might enable legendary interactive development.
How to Render a (Hierarchical) Tree in Asciidoctor
Showing a hierarchical tree, like a file system directory tree, in Asciidoctor is surprisingly hard. We use PlantUML to render the tree on all common platforms.
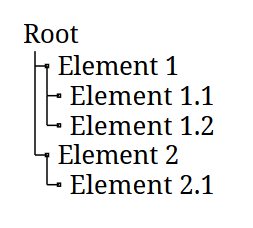
This tree is rendered from the following code:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | [plantuml, format=svg, opts="inline"] ---- skinparam Legend { BackgroundColor transparent BorderColor transparent FontName "Noto Serif", "DejaVu Serif", serif FontSize 17 } legend Root |_ Element 1 |_ Element 1.1 |_ Element 1.2 |_ Element 2 |_ Element 2.1 end legend ---- |
It works on all Asciidoctor implementations that support asciidoctor-diagram and renders well in both HTML and PDF. Readers can select the text (i.e. it’s not an image), and we don’t need to ship additional files.
We might want to externalize the boilerplate:
1 2 3 4 5 6 7 8 9 10 11 12 | [plantuml, format=svg, opts="inline"] ---- !include asciidoctor-style.iuml legend Root |_ Element 1 |_ Element 1.1 |_ Element 1.2 |_ Element 2 |_ Element 2.1 end legend ---- |
1 2 3 4 5 6 | skinparam Legend { BackgroundColor transparent BorderColor transparent FontName "Noto Serif", "DejaVu Serif", serif FontSize 17 } |
Thanks to PlantUML’s impressive reaction time, we soon won’t even need Graphviz installed.
Please find all details in the example repository and example HTML / example PDF rendering.
Inline Display of Error / Warning / Info Annotations in Eclipse
tl;dr: A prototype implementation shows all error, warning, and info annotations (“bubbles” in the left ruler) in Eclipse Java editor as inline text. Thus, we don’t have to use the mouse to view the error message. The error messages update live with changes in the editor.
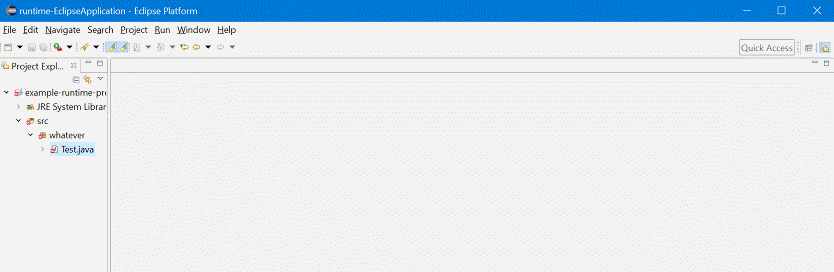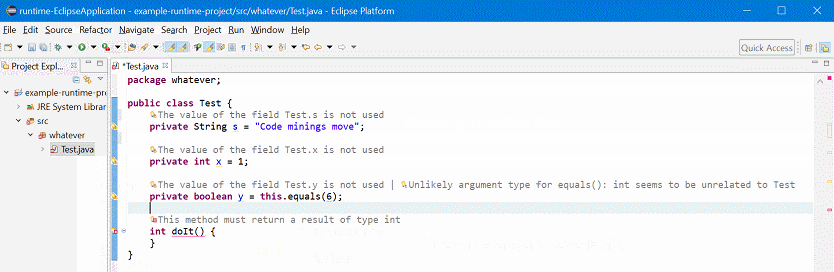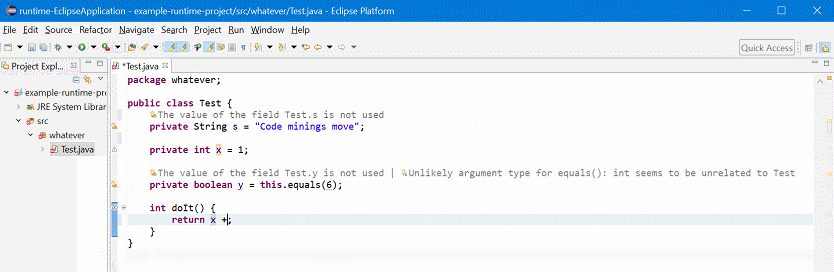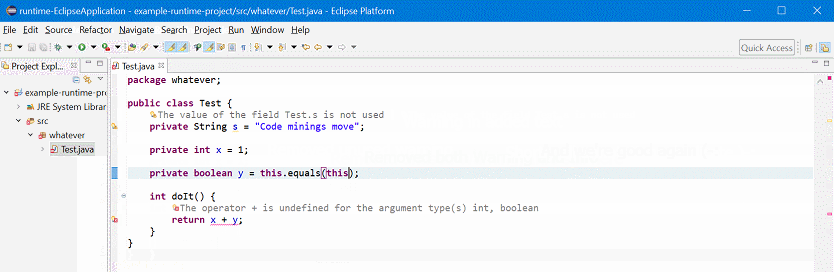
I’m an avid keyboard user. If I have to touch the mouse, something is wrong. Eclise has tons of shortcuts to ease your live, and I use and enjoy them every day.
However, if I had an error message in e.g. my Java file, and I couldn’t anticipate the error, I had several bad choices:
- Opening the Problems view and navigating to the current error (entries in the Problems view are called “markers” by Eclipse)
- Moving the mouse over the annotation in the left ruler (“annotation” in Eclipse lingo)
- Guessing
Not so long ago, Angelo Zerr and others implemented code mining in Eclipse. This feature displays additional information within a text file without changing the actual contents of the file. Sounds like a natural fit for my problem!
I first tried to implement the error code mining based on markers, (Bug 540443). This works in general. However, markers are bound to the persisted state of a file, i.e. how a file is saved to disk. So they are only updated on saving.
Most editors in Eclipse are more interactive than that: They update their error information based on the dirty state of the editor, i.e. the text that’s currently in the editor. This feels way more natural, so I tried to rewrite my error code mining based on annotations. The current prototype is shown in above’s screencast.
The code is attached to Bug 547665. The prototype looks quite promising.
As above’s screencast shows, I have at least one serious issue to resolve: When the editor is saved, all code minings briefly duplicate. Thankfully, they get back to normal quickly.
Xtext Editors within Sirius Diagrams – the Best of both Worlds!
tl;dr: Altran’s Xtext / Sirius Integration provides the full Xtext experience for Sirius direct editors (a.k.a. pressing F2 in diagram) and properties editors. It’s highly configurable, well-documented, and released under EPL 2. I presented it at EclipseCon 2018. We intend to contribute this to the Sirius project.
Example of Xtext’s error checking and auto-completion support within Sirius diagram figure
First Eclipse DemoCamp in Eindhoven: A Great Start and Even Greater Community

Yesterday, we held the first Eclipse DemoCamp ever in Eindhoven, at the Altran office. About 40 people from a dozen different companies joined in and enjoyed the nice dinner buffet.
 Marc Vloemans of Eclipse Foundation kicked off the DemoCamp with a short introduction: DemoCamps are about showing the great work members of the Eclipse community contribute – committers and users alike. Marc emphasized the possibilities of sharing the work between different groups and projects, vastly simplified by the Open Source concept.
Marc Vloemans of Eclipse Foundation kicked off the DemoCamp with a short introduction: DemoCamps are about showing the great work members of the Eclipse community contribute – committers and users alike. Marc emphasized the possibilities of sharing the work between different groups and projects, vastly simplified by the Open Source concept.
Next up was Karsten Thoms of itemis. He swept the audience with an awesome intro – go see it if you have the chance, for example at the DemoCamp Bonn next week or (most probably) EclipseCon Europe in October! Without spoiling the fun, let’s say it gave A New Hope …
 Karsten reported on the many changes he and more than 100 other community members contributed to the Eclipse Platform for the Photon Release Train. He showed lots of examples of the general speed improvements of Eclipse Photon. Also, the Run Configuration’s “Add all required Plug-ins” button finally fulfills its promise!
Karsten reported on the many changes he and more than 100 other community members contributed to the Eclipse Platform for the Photon Release Train. He showed lots of examples of the general speed improvements of Eclipse Photon. Also, the Run Configuration’s “Add all required Plug-ins” button finally fulfills its promise!
 Marc Hamilton explained Altran’s approach for real-world complex modeling environments based on half a dozen Eclipse technologies. At the end, there is always some software produced. Using a modeling approach, most of the actual software production is pushed to generators, while the engineers focus on describing the issue at hand in domain-specific languages.
Marc Hamilton explained Altran’s approach for real-world complex modeling environments based on half a dozen Eclipse technologies. At the end, there is always some software produced. Using a modeling approach, most of the actual software production is pushed to generators, while the engineers focus on describing the issue at hand in domain-specific languages.
Marc showed how EMF, OCL, QVTo, Acceleo, EGF, Xtext, and Sirius are used, and listed the advantages, drawbacks and a wishlist for each technology.
During the break, we had the opportunity to pick up stickers provided by Karsten and discuss with other members of the community.


After the break, we enjoyed the talk of Mélanie Bats, arriving directly from Obeo in Toulouse. She showed new features of Sirius 6, most prominently the ELK layout integration and the magic connector tool to auto-select applicable connections.
 Furthermore, she gave an outlook on the future of Sirius both within Eclipse and in the Web. She envisioned a Graphical Server Protocol akin to the Language Server Protocol to federate diagramming providers from the clients.
Furthermore, she gave an outlook on the future of Sirius both within Eclipse and in the Web. She envisioned a Graphical Server Protocol akin to the Language Server Protocol to federate diagramming providers from the clients.
 Last but not least, Holger Schill of itemis presented the new features of Xtext 2.14. He reported on the huge effort required to get Xtext fully compatible with Java 9, 10, and Junit 5 in all supported environments – and there are plenty! Other notable enhancements include code mining support (showing additional information within the editor without changing the file) and support for new Project / File wizards. The latter ones do not only create plain wizards, but provide a rich API to create customized wizards without the usual hassle of creating SWT dialogs.
Last but not least, Holger Schill of itemis presented the new features of Xtext 2.14. He reported on the huge effort required to get Xtext fully compatible with Java 9, 10, and Junit 5 in all supported environments – and there are plenty! Other notable enhancements include code mining support (showing additional information within the editor without changing the file) and support for new Project / File wizards. The latter ones do not only create plain wizards, but provide a rich API to create customized wizards without the usual hassle of creating SWT dialogs.
We presented a small gift to all the speakers, who spread the word in the community on their own expenses — Huge thanks to Marc, Karsten, Marc, Mélanie, and Holger!

Lots of community members stayed to discuss the presentations and talk to the creators of the technology we use every day.
We enjoyed the DemoCamp a lot. We’re looking forward to have even more talks, topics, and attendees next time!


Eclipse DemoCamp Photon in Eindhoven on July 4: Platform, Sirius, Xtext, and more!
tl;dr: Altran organizes the first Eclipse DemoCamp in Eindhoven to celebrate the Photon Release Train on July 4, 17:00 hrs. Register today! We have Mélanie Bats of Obeo talking about Sirus 6, our own Marc Hamilton summarizing lessons learned from 10 years worth of MDE projects, and itemis’ Karsten Thoms and Holger Schill reporting about the latest features of Eclipse Platform 4.8 and Xtext 2.14, respectively.

After hosting the Sirius Day in April, we’re already looking at the next Eclipse event at Altran Netherlands: We’ll host the first Eclipse DemoCamp in Eindhoven to celebrate the Photon Release Train on July 4, 17:00 hrs.
We’ll start off at 17:00 hrs with a small dinner, so we all can enjoy the talks without starving. Afterwards, we have a very exiting list of speakers:
-
Mélanie Bats, CTO of Obeo, will tell us about What’s new in Sirius 6.
Major Changes in Sirius 6:
-
Sirius now supports an optional integration with ELK for improved diagram layouts: specifiers can configure which ELK algorithm and parameters should be used for each of their diagrams, directly inside the VSM (ticket #509070). This is still considered experimental in 6.0.
-
A new generic edge creation tool is now available on all Sirius diagrams. With it, end users no longer have to select a specific edge creation tool in the palette, but only to choose the source and target elements (ticket #528002).
-
Improved compatibility with Xtext with an important bug fix (ticket #513407). This is a first step towards a better integration with Xtext, more fixes and improvements will come during the year.
-
It is now possible for specifiers to configure the background color of each diagram. Like everything else in Sirius, the color can be dynamic and reflect the current state of the model. (ticket #525533).
-
When developing a new modeler, it is now possible to reload the modeler’s definition (.odesign) from an Eclipse runtime if the definition has changed in the host that launched the runtime. This is similar to “hot code replace” in Java, but for VSMs, and avoids stopping/restarting a new runtime on each VSM change (ticket #522407).
-
In the VSM editor, when editing an interpreted expression which uses custom Java services, it is now possible to navigate directly to a service’s source code using F3 (ticket #471900).
A more visual overview can be found in the Obeo blog.
-
-
Altran’s own Marc Hamilton shares Altran’s experience developing MDE applications with Eclipse technology.
Altran Netherlands develops Eclipse-based model-driven applications for its customers for several years.
In this talk, we share our experience with different modeling technologies like Acceleo, OCL, QVTo, EGF, Sirius, Xtext, and others. -
What’s new in Xtext 2.14 will be presented by Xtext committer of itemis, Holger Schill.
Major Changes in Xtext 2.14:
- Java 9 and 10 Support
- JUnit 5 Support
- New Grammar Annotations
- Create Action Quickfix
- Code Mining Support
- New Project and File Wizard
- Improved Language Server Support
- Performance Improvements
Please check the Release Notes for details.
-
Yet another overview by Karsten Thoms, of itemis with his talk Approaching Light Speed – News from the Eclipse Photon Platform.
The Eclipse Photon simultaneous release comes this year with a plethora of new features and improvements that will continue the Eclipse IDE keeping the #1 flexible, scalable and most performing IDE!
This session will give a guided tour through the new features and changes in Eclipse Photon. Due to the vast amount of noteworthy stuff the focus of this talk is on the Eclipse Platform Project, covering JDT only roughly. You will see usability improvements, useful new API for platform developers and neat features for users. Besides visible changes, the platform project team has paid special attention on stability, performance and resource consumption tuning. In this talk, I will give some insights how the team has worked on that.
Come and see the incredible achievements the platform team and its growing number of contributors made to bring you the best Eclipse IDE ever!
More talks are in discussion. Please propose your talk to us; we’d be especially happy to include more local speakers in the lineup.
We’ll have a break and some get-together afterwards, so there is plenty of opportunity to get in touch with the speakers and your fellow Eclipse enthusiasts in the region.
The DemoCamp will take place at the Altran office in Eindhoven. Please refer to the Eclipse wiki for all details and register now to secure your spot at the first Eclipse DemoCamp in Eindhoven!
High-Performance Interpreters for JetBrains MPS
tl;dr An interpreter framework prototype based on GraalVM / Truffle shows two orders of magnitude better performance than the previous implementation. Vote for Java Annotation Processor support in MPS to help this effort.
Overview
At the great MPS Meetup last week in Munich I had a chance to give a talk on the MPS Interpreter Framework I worked on at itemis. The slides are available, and the talk was recorded.
We had an enthusiastic audience with lots of questions. This skewed my timing a bit, thus I could only spend a few minutes on my latest experiments in this field: A new take on the interpreter framework, based on GraalVM / Truffle. Meinte Boersma inspired this blog post to add more details — thanks a lot for the motivation, Meinte!
To shortly recap the first part of my talk: Interpreters are easy to implement, especially if an MPS language avoids the usual boilerplate and integration in the typesystem gets rid of instanceof and casting orgies. This is pretty much the the state of the existing Interpreter Framework, which is used in a lot of real-world projects (e.g. KernelF or at the Dutch tax office).
This leaves us with one big drawback of interpreters: Usually, their performance is pretty bad. Enter GraalVM!
GraalVM is a highly optimized just-in-time-compiler for Java. It also provides an API to the code running on the JVM, and thus can be leveraged by Truffle.
Truffle is a library to implement high-performance interpreters, it uses all the tricks in the book: AST rewriting, partial evaluation, polymorphic inline caches, …, you name it. This leads to pretty impressive performance, like 90 % of the hand-optimized V8 JavaScript engine. Truffle makes use of GraalVM, but also runs on a regular JVM.
Another part of GraalVM ecosystem is called Polyglot. It allows interaction and optimization across languages, e.g. starting a JavaScript program, calling an R routine, which calls Ruby, which uses JavaScript, and all of this without data serialization or performance drawback.
Incidentally, Oracle released GraalVM 1.0 this week. We might see a lot more traction in this field.
Based on the first non-representative, non-exhaustive tests, GraalVM delivers big time:
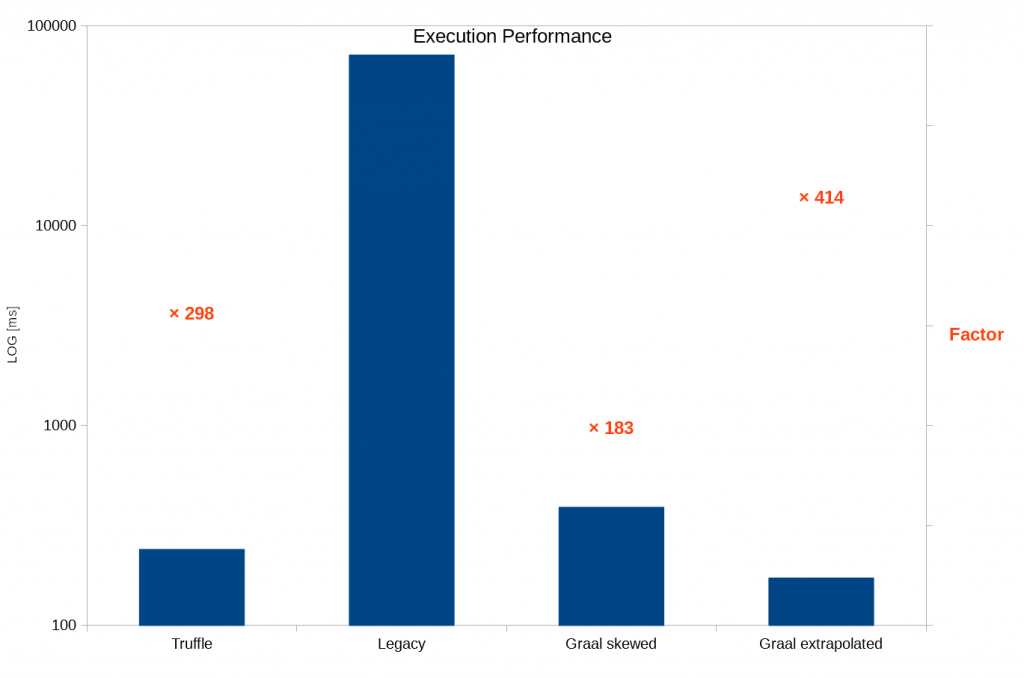
- Truffle runs within MPS, but on a regular JVM (i.e. without GraalVM JIT).
- Legacy is the existing interpreter framework within MPS.
- Graal skewed runs Truffle within MPS on a GraalVM JIT. I must have messed up something there, as the performance should be better than pure Truffle. Also, MPS itself felt quite sluggish with this configuration.
- Graal extrapolated uses the stand-alone version (outside MPS) as a comparison what should be achievable.
Please note that the test program was quite basic, probably leading to overly optimistic results. However, I used a pretty old version of GraalVM (shipped with JDK9 on Windows) and Truffle (0.30), and reportedly newer versions perform a lot better. So in total, I think we can expect two orders of magnitude better performance.
Technical Details
GraalVM
GraalVM is available in a special build of Java8 on Linux and Mac. Java9 on Windows and Mac and Java10 on Linux also contain a (probably outdated) version of GraalVM.
As my current development environment is on Windows, I first tried to build the source version of GraalVM on Windows. I finally got it built, but the resulting java.exe segfaulted even on java.exe -version.
The next best way was to get MPS running on Java9. If we’re using Java8 for compilation and Java9 only as a runtime environment, we only need a few adjustments to the MPS sources. I put my hack on github. Be warned: it contains a few hard-coded local paths!
Truffle
Truffle relies on Java Annotation Processors, a standardized way to extend the Java compiler.
MPS internally uses the Eclipse java compiler, which fully supports annotation processors. The Eclipse java compiler also supports both the IntelliJ compiler infrastructure and the Java standard for calling compilers, but MPS uses a hand-knitted interface to the compiler without annotation processor support. I opened a Feature request for MPS to support Annotation Processors, so please upvote if you’re interested in high-performance interpreters.
My aforementioned hack also contains changes to enable the required annotation processors within MPS.
TruffleInterpreter Language
I started the language from scratch for several reasons:
- The existing Interpreter language was the first thing I implemented in MPS, and I learned a lot since then.
- The interpreter should become its own language aspect, thus requiring considerable changes anyway.
- Understanding Truffle and generating the correct code for it is hard enough, I didn’t want to add the burden of non-fitting abstractions.
- We need quite some additional information for the new backend.
Obviously, I kept the nice parts regarding concise syntax and typesystem integration.
I did not spend much time yet on beautifying the language, but I think the general idea is already recognizable.
As a playground, I implemented SimpleLanguage as shipped with Truffle in both MPS interpreter frameworks. (Please find screenshots of the complete interpreters at the end of this post.)
Let’s look at a few examples from both interpreters:
-
Invoke Expression
Invoke maps quite directly.Legacy

Truffle

-
Plus Expression
Plus is also similar, but we can spot some differences:- Mixtures of types are handled automatically by Truffle
- Truffle adds programmatic type guards for the String overload
Legacy

Truffle

-
Typemapping
The actual typemapping is very similar. However, Truffle needs to know about the run-time (aka interpretation-time) typesystem including type checks, type casts, and implicit casts.Legacy

Truffle

The Truffle variant contains a few more hints only accessible via inspector.
I guess a converter from legacy to Truffle interpreters should be feasible, but the result might not run out-of-the-box.
Implementation
The implementation faced three main issues:
-
Generating the correct code for Truffle
Truffle is very picky about what code it accepts, e.g. some fields must be final, but others must not. There seems no way for annotation processors to emit messages during compilation. Thus, we generate some code, and it either works or not, without any hints (in some cases we pass the compilation steps and get hints during execution).
-
Providing the generated truffle interpreter to the Truffle runtime
Truffle expects all its languages to be available in its classpath at startup.
So currently, we cannot change the interpreters after the first invocation of any (!) interpreter.
There might be a way to add languages at runtime, but my hunch is this would get us into never-ending classloading issues. See below for thoughts on a better approach. -
Running annotation processors the same time as the regular compilation
The code generated by MPS contains calls to classes only generated by Truffle’s annotation processors, so we have to execute both in the same step.
Re-implementing Truffle’s generators in MPS is also not an option, both from their size and complexity.This picture compares the input MPS Concepts mentioned in the interpreter, Java source files generated by MPS, and produced Java classes

A small snippet of the Truffle-generated code. Who wants to tell me where I took it from?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41private Object executeGeneric_generic1(VirtualFrame frameValue, int state) {
Object leftValue_ = this.left_.executeGeneric(frameValue);
Object rightValue_ = this.right_.executeGeneric(frameValue);
if ((state & 2) != 0 && leftValue_ instanceof Long) {
long leftValue__ = (Long)leftValue_;
if (rightValue_ instanceof Long) {
long rightValue__ = (Long)rightValue_;
try {
return this.specialization(leftValue__, rightValue__);
} catch (ArithmeticException var14) {
Lock lock = this.getLock();
lock.lock();
try {
this.exclude_ |= 1;
this.state_ &= -3;
} finally {
lock.unlock();
}
return this.executeAndSpecialize(leftValue__, rightValue__);
}
}
}
if ((state & 4) != 0 && SLxTypesGen.isImplicitBigInteger((state & 48) >>> 4, leftValue_)) {
BigInteger leftValue__ = SLxTypesGen.asImplicitBigInteger((state & 48) >>> 4, leftValue_);
if (SLxTypesGen.isImplicitBigInteger((state & 192) >>> 6, rightValue_)) {
BigInteger rightValue__ = SLxTypesGen.asImplicitBigInteger((state & 192) >>> 6, rightValue_);
return this.specialization(leftValue__, rightValue__);
}
}
if ((state & 8) != 0 && this.guardSpecialization(rightValue_, leftValue_)) {
return this.specialization(leftValue_, rightValue_);
} else {
CompilerDirectives.transferToInterpreterAndInvalidate();
return this.executeAndSpecialize(leftValue_, rightValue_);
}
}
Lifecycle

- We start by defining our Language SimpleLanguage as usual. As an example, we define a concept SlPlus.
- We create a TruffleInterpreter for SimpleLanguage. In the interpreter, we create the evaluator for SlPlus.
- The generator of TruffleInterpreter turns the evaluator for SlPlus into a Java class named SlPlusNode that inherits from TruffleNode.
- Once we want to evaluate our instance model of SimpleLanguage, the TruffleInterpreter framework converts all instances of SlPlus (i.e. MPS nodes of concept SlPlus) into instances of SlPlusNode (i.e. Java objects of class SlPlusNode).
- The TruffleInterpreter framework invokes the TruffleRuntime on the recently created SlPlusNode object.
- We can retrieve the result of our interpretation, e.g. a java.lang.Long object, from TruffleRuntime.
Truffle requires all evaluated nodes to be TruffleNodes to do its magic.
This implies some overhead to convert MpsNodes into TruffleNodes, but allows us to execute the interpreter without model access afterwards. We can even run the interpreter in a different thread and update our editor once the calculation is done.
Language Interoperability
The Polyglot part of GraalVM allows arbitrary mixture of languages. The prototype contains an example to call JavaScript:

(You have to know this joke!)
Polyglot supports language interoperability with complex types, but I didn’t implement this yet in this prototype.
Future Work
Turn Prototype into Production Code
This blog post is about a prototype, meant to explore the possibilities, pitfalls and benefits. It breaks quickly if you try something different. It does not implement all features of Truffle. The generator does not need to be rewritten from scratch, but needs a serious overhaul. The language is too close to Truffle specifics, and thus hard to use if you don’t know about Truffle.
Interpreter Language Aspect
Interpreters should be a separate language aspect, the same way as typesystem or constraints. At the MPS Meetup we agreed that executing your models is highly valuable in lots of domains; a language aspect emphasizes this importance.
Also, having a language aspect should improve integration with the rest of the MPS ecosystem and ease classloading for interpreters.
One Interpreter for all Languages
The current implementation registers every interpreter as its own Truffle language; the idea was to leverage Polyglot for language interaction. However, this leads to classloading issues.
An alternative would be to look at interpreters similar to editors: In MPS, we have a standard editor for all concepts. If we need to, we can provide other editors triggered by editor hints. Similarly, we could have one standard language (from a Truffle point of view), and all interpreters contribute to this standard Truffle language. We might register a few secondary Truffle languages by default, so we don’t have to restart MPS as soon as anybody wants to use an “interpreter hint”.
This should maintain MPS language extensibility, as any MPS language can contribute standard interpreters for any concept, or might register secondary interpreters with an “interpreter hint”.
I’m not sure yet what to do about nodes without any known interpreter. We might want to ignore them, or traverse their subnodes to find something we can interpret.
Fine-tuning MpsNode → TruffleNode Conversion
The current implementation converts an arbitrary selection of MpsNodes into TruffleNodes prior to invoking the interpreter. We could think of other approaches:
- Convert the starting node and all contained and related nodes up to a specific depth; At the end of each branch, we’d insert a “ReloadNode” to convert more nodes once it’s needed.
- We could keep the converted TruffleNodes in memory and update them on any changes to the underlying MpsNodes (aka “Shadow model”).
- It should be feasible to make our TruffleNodes serializable. Thus, we could save and reload them on MPS restart, or even execute them outside MPS.
Typesystem Integration
As mentioned above, the Truffle interpreter needs to know a lot about runtime types. At least for some of the information, we might be able to infer it from the MPS typesystem aspect.
Scoping Integration
If our interpreted language had nested scopes, maybe even including shadowing, the interpreter needs to know this. We might be able to infer this knowledge from the MPS constraints aspect.
DSL for Objects
Polyglot supports direct interaction between different languages on complex types. I only scratched this topic yet, but so far this seems to be very exiting both to interact with non-MPS Truffle languages (GraalVM ships with implementations of JavaScript, R, and Ruby) and to enable language composition at runtime.
Truffle bases the interaction on a concept called Shapes; I’m pretty sure there could be a DSL to ease their usage.
Debugger Integration
For smaller interpreted programs, something similar to the Trace Explorer available for the legacy Interpreter could be very useful.
GraalVM supports exposing the interpreted program via the standard JVM debugging APIs, including breakpoints and introspection. Contrary to popular belief, a Java program can debug itself, as long as the debugger and the target (i.e. interpreter) run in different threads. So we might be able to use the debugging UI included in MPS (as inherited from IntelliJ) to debug our interpreted program. A long time ago, I wrote a proof-of-concept of this idea for the legacy Interpreter, so we know we can get to the appropriate APIs.
Ahead-of-Time Compilation Support
A yet unmentioned part of GraalVM is called Sulong: An ahead-of-time-compiler for Truffle languages. I have no experience with Sulong, so I can only guess about its possibilities.
Especially in combination with serializable TruffleNodes this might lead to production-ready performance outside of MPS, thus rendering a separate implementation of the same logic in a generator obsolete.
Edit: I mixed up Sulong and SubstrateVM, as Oleg points out in the comments.
Appendix: Complete Interpreters
Legacy

Truffle

Do we need Eclipse Commons?
tl;dr Vote at https://github.com/enikao/eclipse-commons/issues/1 in favor or against creating an Eclipse Commons (akin to Apache Commons) project.
Rationale
Have you ever done an Eclipse / EMF project without implementing this code?
1 2 3 4 5 6 7 8 | public static IResource toIResource(URI uri) { if (uri.isPlatformResource()) { return ResourcesPlugin.getWorkspace().getRoot() .findMember(uri.toPlatformString(true)); } return null; } |
I haven’t. And I’m tired of writing this code over and over again. Especially as I usually need more than one take to get it right (for example, the version above does not handle URIs pointing to non-existing IResources).
It already has been implemented several times. But I don’t want to introduce complex dependencies for reusing these implementations.
There are lots of other commonly reused code snippets, like
- java.net.URI ↔ org.eclipse.emf.common.util.URI
- In an JUnit test, wait for the workspace to be ready
- Create an IStatus without breaking your fingers
- …
I therefore propose an Eclipse Commons project. This project would collect small utilities with minimal additional dependencies for common reuse.
Counter-Arguments
Allow me to anticipate some counter-arguments.
This code should be in the original project!
Yes, it should. But it is not. Some reasons might be personal preferences by the maintainers (“This code snippet is too short to be useful”), contextual arguments (“An URI cannot be generically represented as an IResource”), or no actual original project (where would the JUnit extensions go?).
(Please note that these are hypothetical reasons, not based on concrete experience.)
We don’t want to repeat the npm desaster with tiny snippets!
I envision Eclipse Commons to be hosted by the Eclipse Foundation (obviously). Therefore, no code that has been in there can just disappear.
This seems like an arbitrary collection of code. Who decides what is in, what is out of scope?
I propose a two-step approach. First, there is a “pile” repository (better name highly appreciated) where almost anything can be proposed. For each new proposal, we would have a vote. Every proposal that passes a threshold of votes (details tbd) and meets the required quality is accepted in Eclipse Commons.
Deployable artifacts are only created from the Eclipse Commons repository.
We definitely do not want to re-implement functionality that’s available on a similar level, like Apache Commons or Google Guava.
That’s chaos! Who creates order?
Besides some sanitation, I would not enforce any “grand scheme of things”. I’d guess Eclipse Commons would contain a quite diverse code base, therefore we don’t need central coordination. Also, there might not be any one party with enough insight into all parts of Eclipse Commons.
If a sizable chunk of code for a common topic agglomerates, it’s a good sign that the original project is really missing something and should adopt this chunk of code. This implies there is a party capable of bringing order to that chunk.
Also, Eclipse Commons should not be misused as a dump for large code base(s) that really should be their own project.
Thoughts on Implementation
Dependencies
Eclipse Commons should be separated in different plug-ins, guided by having the least possible dependencies. We might have one plug-in org.eclipse.commons.emf only depending on org.eclipse.core.runtime, org.eclipse.core.resources, and org.eclipse.emf.*. Another one might be org.eclipse.commons.junit depending only on core Eclipse and JUnit plug-ins, etc.
We should have strict separation between UI and non-UI dependent code. Where applicable, we should separate OSGi-dependent code from OSGi-independent implementations (as an example, a class EcoreUtil2 might go to the plug-in org.eclipse.commons.emf.standalone, as EMF can be used without OSGi).
As these plug-ins are meant solely for reuse, they should re-export any dependencies required to use them. We must avoid “class hierarchy incomplete” or “indirectly required” errors for Eclipse Commons users.
Versioning and Evolution
I propose semantic versioning. Regarding version x.y.z, we increase y every time some new proposal is migrated from “pile”. We reset z for every y increment to 0, and increase z for maintenance and bug fixes. x might be increased when code chunks are moved to an original project or one of our dependencies changes (see below). Every JavaDoc must contain @since for fine-grained versioning.
We should be “forever” (i.e. the foreseeable future) backwards-compatible, so we avoid any issues with upgrading. If code chunks are moved to an original project, this code should still be available within Eclipse Commons, but should be marked as @deprecated. Removing these chunks would require Eclipse Commons users to move to the newest version of the original project, but they might be not be able to do this. For the same reason, we cannot delegate from the (now deprecated) Eclipse Commons implementation to the original project.
I’m not sure what to do if a new proposal required a major change in our dependencies. As example, the existing plug-in org.eclipse.commons.emf might depend on org.eclipse.emf in version 2.3, but the new proposal required changes only introduced in EMF v2.6. We might want to go through with such a change, or create a separate plug-in with stricter dependencies.
Required Quality
I think the bar for entering “pile” should be rather low. This allows voting how useful the addition might be to others, and also allows community effort in reaching the desired quality. As we expect more or less independent utilities, improvements by others than the original authors should be easily possible without much required ramp-up.
On the other hand, code that enters Eclipse Commons must be pretty good. We want to keep this “forever”, and don’t want to spend the next year cleaning up after a have-backed once-off addition. This includes thorough documentation and tests.
We should care for naming, especially symmetry in naming. Having two methods IResource UriUtils.toIResource(URI) and URI IResourceTool.asUri(IResource) is highly undesirable.
Next Steps
I created a (temporary) repository at https://github.com/enikao/eclipse-commons, including a (hopefully) thorough implementation of aforementioned utility method.
What do you think of Eclipse Commons? Would you use it? Contribute? Help in maintaining it? How many votes should be the “pile” → Eclipse Commons threshold? And what would be a better name than “pile”?
Please leave your votes and comments at github.
If there was sufficient interest, the next step would be an Eclipse Incubation Project proposal.
Combine Xcore, Xtend, Ecore, and Maven
Update: Christian found a workaround for compiling code that references Ecore types. We adjusted the article.
Lots of thanks to Christian for figuring this out together.
The complete example is available on github.
Also, we included all the files as Listings at the end of the article. They are heavily commented.
Objective
Inside an Eclipse plugin, we have EMF models defined in both Xcore and Ecore, using types from each other. Also, we have a Helper Xtend class that’s called from Xcore and uses types from the same model. We want to build the Eclipse Plugin with Maven. We also don’t want to commit any generated sources (from Xtend, Xcore, or Ecore).
Issue
Usually, we would use xtend-maven-plugin to build the Xtend classes, xtext-maven-plugin to build the Xcore model, and MWE2 to build the Ecore model.
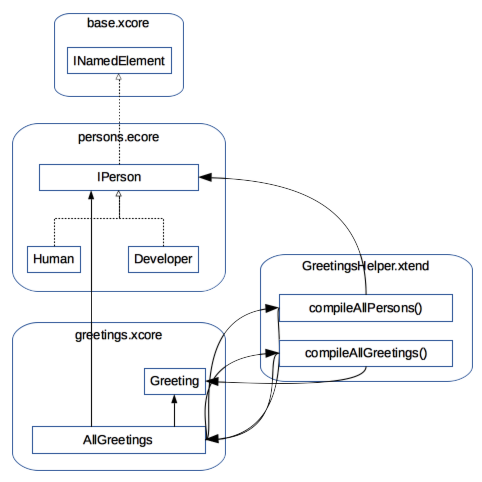
However, we have a cyclic compile-time dependency between AllGreetings calling GreetingsHelper.compileAllGreetings() which receives a parameter of type AllGreetings. We also have a cyclic dependency between AllGreetings calling GreetingsHelper.compileAllPersons() and using IPerson type.
Solution
Java (and Xtend) can solve such cycles in general, but only if they process all members at the same time. Thus, we need to make sure both Xtend and Xcore are generated within the same Maven plugin.
We didn’t find a way to include the regular Ecore generator in the same step, so we keep this in a separate MWE2-based Maven plugin.
For generating persons.ecore, we call an MWE2 workflow from Maven via exec-maven-plugin. The workflow itself gets a bit more complicated, as we use INamedElement from base.xcore as a supertype to IPerson inside persons.ecore. Thus, we need to ensure that base.xcore is loaded, available, and can be understood by the Ecore generator.
Afterwards, we use xtext-maven-plugin to generate both Xtend and the two Xcore models. To do this, we need to include all the required languages and dependencies into one single plugin in our maven pom.
The first version could not compile GreetingsHelper.compileAllPersons() because it referenced types from persons.ecore, and these could not be resolved by the EMF validator. As a workaround, we disabled the validator in the workflow.
Remarks
- We developed this using Eclipse Mars.2.
- The example project should be free of errors and warnings, and builds in all of Eclipse, MWE2, and Maven.
In Maven, you might see some warnings due to an Xtext bug. It should not have any negative impact.
- When creating the Ecore file, make sure only to use built-in types (like EString) from http://www.eclipse.org/emf/2002/Ecore. They may be listed several times.
- In our genmodel file, Eclipse tends to replace this way of referring to platform:/resource/org.eclipse.emf.ecore/model/Ecore.genmodel#//ecore by something like ../../org.eclipse.emf.ecore/model/Ecore.genmodel#//ecore. This would lead to ConcurrentModificationException in xtext-maven-plugin or MWE2, or “The referenced packages ”{0}” and ”{1}” have the same namespace URI and cannot be checked at the same time.” when opening the GenModel editor.
In this case, open the genmodel file with a text editor and use the platform:/resource/org.eclipse.emf.ecore/model/Ecore.genmodel#//ecore form in the genmodel:GenModel#usedGenPackages attribute. Sadly, this needs to be fixed every time the Genmodel Editor saves the file.
- The Xcore builder inside Eclipse automatically picks up the latest EMF complianceLevel, leading to Java generics support in generated code. The maven plugin does not use the latest complianceLevel, thus we need to set it explicitly.
- The modelDirectory setting in both Xcore and Ecore seem to be highly sensitive to leading or trailing slashes. We found it safest not to have them at all.
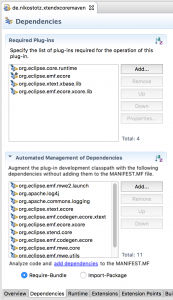 Using all the involved generators (MWE2, Xcore, Xtend, …) requires quite a few dependencies for our plugin. As a neat trick, we can define them in build.properties rather than MANIFEST.MF. This way, they are available at build time, but do not clog our run-time classpath. As we can see on the right, they are also listed separately in the Eclipse dependency editor.
Using all the involved generators (MWE2, Xcore, Xtend, …) requires quite a few dependencies for our plugin. As a neat trick, we can define them in build.properties rather than MANIFEST.MF. This way, they are available at build time, but do not clog our run-time classpath. As we can see on the right, they are also listed separately in the Eclipse dependency editor.- maven-clean-plugin seems to be quite sensitive how its filesets are described. Even when disregarding the .dummy.txt entries in our pom, the *-gen directories were only cleaned if we listed them in separate fileset entries.
- The workflow should reside within an Eclipse source folder. To separate it from real sources, we created a new source folder named workflow.
Listings
Project Layout
GreetingsHelper.xtend
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | package de.nikostotz.xtendxcoremaven.greetings.helper import de.nikostotz.xtendxcoremaven.greetings.AllGreetings class GreetingsHelper { // This method is called from greetings.xcore and has AllGreetings as parameter type, // thus creating a dependency circle def static String compileAllGreetings(AllGreetings it) { var totalSize = 0 // We access the AllGreetings.getGreetings() method in two different ways // (for-each-loop and map) to demonstrate different error messages if we omit // 'complianceLevel="8.0"' in greetings.xcore for (greeting : it.getGreetings()) { totalSize = totalSize + greeting.getMessage().length } ''' Greetings: «it.getGreetings().map[greeting | greeting.getMessage()].join(", ")» ''' } def static String compileAllPersons(AllGreetings it) { // AllGreetings.getPersons() refers to type IPerson, which is defined in Ecore. // This only works if we disable the validator in the MWE2 workflow. ''' Hello Humans: «it.getPersons().map[person | person.describeMyself()].join(", ")» ''' } } |
base.xcore
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | @GenModel( // This sets the target directory where to put the generated classes. // Make sure NOT to start or end with a slash! // Doing so would lead to issues either with Eclipse builder, MWE2 launch, or Maven modelDirectory="de.nikostotz.xtendxcoremaven/xcore-gen", // required to fix an issue with xcore (see https://www.eclipse.org/forums/index.php/t/367588/) operationReflection="false" ) package de.nikostotz.xtendxcoremaven.base // This enables usage of the @GenModel annotation above. The annotation would work without // this line in Eclipse, but Maven would fail. // (WorkflowInterruptedException: Validation problems: GenModel cannot be resolved.) annotation "http://www.eclipse.org/emf/2002/GenModel" as GenModel interface INamedElement { String name } |
persons
persons.ecore
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | < ?xml version="1.0" encoding="UTF-8"?> <ecore:epackage xmi:version="2.0" xmlns:xmi="http://www.omg.org/XMI" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:ecore="http://www.eclipse.org/emf/2002/Ecore" name="persons" nsURI="de.nikostotz.xtendxcoremaven.persons" nsPrefix="persons"> <eclassifiers xsi:type="ecore:EClass" name="IPerson" abstract="true" interface="true" eSuperTypes="base.xcore#/EPackage/INamedElement"> <eoperations name="describeMyself" lowerBound="1" eType="ecore:EDataType http://www.eclipse.org/emf/2002/Ecore#//EString"></eoperations> </eclassifiers> <eclassifiers xsi:type="ecore:EClass" name="Human" eSuperTypes="#//IPerson"> <estructuralfeatures xsi:type="ecore:EAttribute" name="knownHumanLanguages" upperBound="-1" eType="ecore:EDataType http://www.eclipse.org/emf/2002/Ecore#//EString"></estructuralfeatures> </eclassifiers> <eclassifiers xsi:type="ecore:EClass" name="Developer" eSuperTypes="#//IPerson"> <estructuralfeatures xsi:type="ecore:EAttribute" name="knownProgrammingLanguages" upperBound="-1" eType="ecore:EDataType http://www.eclipse.org/emf/2002/Ecore#//EString"></estructuralfeatures> </eclassifiers> </ecore:epackage> |

persons.genmodel
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | < ?xml version="1.0" encoding="UTF-8"?> <genmodel:genmodel xmi:version="2.0" xmlns:xmi="http://www.omg.org/XMI" xmlns:ecore="http://www.eclipse.org/emf/2002/Ecore" xmlns:genmodel="http://www.eclipse.org/emf/2002/GenModel" modelDirectory="de.nikostotz.xtendxcoremaven/emf-gen" modelName="Persons" importerID="org.eclipse.emf.importer.ecore" complianceLevel="8.0" copyrightFields="false" importOrganizing="true" usedGenPackages="base.xcore#/1/base platform:/resource/org.eclipse.emf.ecore/model/Ecore.genmodel#//ecore"> <!-- Eclipse tends to replace this way of referring to the Ecore genmodel by something like "../../org.eclipse.emf.ecore/model/Ecore.genmodel#//ecore". This would lead to ConcurrentModificationException in xtext-maven-plugin or MWE2, or "The referenced packages ''{0}'' and ''{1}'' have the same namespace URI and cannot be checked at the same time." when opening the GenModel editor. --> <foreignmodel>persons.ecore</foreignmodel> <genpackages prefix="Persons" basePackage="de.nikostotz.xtendxcoremaven.persons" disposableProviderFactory="true" ecorePackage="persons.ecore#/"> <genclasses image="false" ecoreClass="persons.ecore#//IPerson"> <genoperations ecoreOperation="persons.ecore#//IPerson/describeMyself"></genoperations> </genclasses> <genclasses ecoreClass="persons.ecore#//Human"> <genfeatures createChild="false" ecoreFeature="ecore:EAttribute persons.ecore#//Human/knownHumanLanguages"></genfeatures> </genclasses> <genclasses ecoreClass="persons.ecore#//Developer"> <genfeatures createChild="false" ecoreFeature="ecore:EAttribute persons.ecore#//Developer/knownProgrammingLanguages"></genfeatures> </genclasses> </genpackages> </genmodel:genmodel> |

greetings.xcore
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 | @GenModel( modelDirectory="de.nikostotz.xtendxcoremaven/xcore-gen", operationReflection="false", // This enables Java generics support in EMF (starting with version 6.0). // If omitted, we'd get a "Validation Problem: The method or field message is undefined" in Maven // because AllGreetings.getGreetings() would return an EList instead of an EList<greeting>, thus // we cannot know about the types of the list elements and whether they have a 'message' property. // In other cases, this leads to error messages like "Cannot cast Object to Greeting". complianceLevel="8.0" ) package de.nikostotz.xtendxcoremaven.greetings // referring to Ecore import de.nikostotz.xtendxcoremaven.persons.persons.IPerson // referring to Xtend import de.nikostotz.xtendxcoremaven.greetings.helper.GreetingsHelper annotation "http://www.eclipse.org/emf/2002/GenModel" as GenModel class AllGreetings { contains IPerson[] persons contains Greeting[] greetings op String compileAllGreetings() { // calling Xtend inside Xcore GreetingsHelper.compileAllGreetings(this) } op String compileAllPersons() { // calling Xtend inside Xcore GreetingsHelper.compileAllPersons(this) } } class Greeting { String message refers IPerson person } |
MANIFEST.MF
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | Manifest-Version: 1.0 Bundle-ManifestVersion: 2 Bundle-Name: %pluginName Bundle-SymbolicName: de.nikostotz.xtendxcoremaven;singleton:=true Bundle-Version: 1.0.0.qualifier Bundle-ClassPath: . Bundle-Vendor: %providerName Bundle-Localization: plugin Bundle-Activator: de.nikostotz.xtendxcoremaven.XtendXcoreMavenActivator Require-Bundle: org.eclipse.core.runtime, org.eclipse.emf.ecore;visibility:=reexport, org.eclipse.xtext.xbase.lib, org.eclipse.emf.ecore.xcore.lib Bundle-RequiredExecutionEnvironment: JavaSE-1.8 Export-Package: de.nikostotz.xtendxcoremaven.greetings.impl, de.nikostotz.xtendxcoremaven.greetings.util, de.nikostotz.xtendxcoremaven.base, de.nikostotz.xtendxcoremaven.base.impl, de.nikostotz.xtendxcoremaven.base.util, de.nikostotz.xtendxcoremaven.persons.persons, de.nikostotz.xtendxcoremaven.persons.persons.impl, de.nikostotz.xtendxcoremaven.persons.persons.util Bundle-ActivationPolicy: lazy |
build.properties
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | # bin.includes = .,\ model/,\ META-INF/,\ plugin.xml,\ plugin.properties jars.compile.order = . source.. = src/,\ emf-gen/,\ xcore-gen/,\ xtend-gen/ src.excludes = workflow/ output.. = bin/ # These work the same as entries in MANIFEST.MF#Require-Bundle, but only at build time, not run-time additional.bundles = org.eclipse.emf.mwe2.launch,\ org.apache.log4j,\ org.apache.commons.logging,\ org.eclipse.xtext.ecore,\ org.eclipse.emf.codegen.ecore.xtext,\ org.eclipse.emf.ecore.xcore,\ org.eclipse.xtend.core,\ org.eclipse.emf.codegen.ecore,\ org.eclipse.emf.mwe.core,\ org.eclipse.emf.mwe.utils,\ org.eclipse.emf.mwe2.lib |
generateGenModel.mwe2
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 | module GenerateGenModel var projectName = "de.nikostotz.xtendxcoremaven" var rootPath = ".." Workflow { // This configures the supported model types for EcoreGenerator. // Order is important. // Should be the same list as in Reader below. bean = org.eclipse.emf.ecore.xcore.XcoreStandaloneSetup {} bean = org.eclipse.xtend.core.XtendStandaloneSetup {} bean = org.eclipse.xtext.ecore.EcoreSupport {} bean = org.eclipse.emf.codegen.ecore.xtext.GenModelSupport {} bean = org.eclipse.emf.mwe.utils.StandaloneSetup { // Required for finding the platform contents (Ecore.ecore, Ecore.genmodel, ...) under all circumstances platformUri = "${rootPath}" // Required for finding above mentioned models inside their Eclipse plugins scanClassPath = true } // As persons.ecore refers to a type inside base.xcore (IPerson extends INamedElement), // we need to load base.xcore before we can generate persons.ecore. component = org.eclipse.xtext.mwe.Reader { // This configures the supported model types for this Reader. // Order is important. // Should be the same list as beans above. register = org.eclipse.emf.ecore.xcore.XcoreStandaloneSetup {} register = org.eclipse.xtend.core.XtendStandaloneSetup {} register = org.eclipse.xtext.ecore.EcoreSupport {} register = org.eclipse.emf.codegen.ecore.xtext.GenModelSupport {} // This asks the Reader to read all models it understands from these directories (and sub-directories). path = "model" path = "src" // Put the models inside a ResourceSet that's accessible by the EcoreGenerator. loadFromResourceSet = {} // This is a workaround to get GreetingsHelper.compileAllPersons() compiled. validate = org.eclipse.xtext.mwe.Validator.Disabled {} } // Generate persons.ecore (via persons.genmodel). component = org.eclipse.emf.mwe2.ecore.EcoreGenerator { genModel = "platform:/resource/${projectName}/model/persons.genmodel" srcPath = "platform:/resource/${projectName}/emf-gen" } } |
pom.xml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 | <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelversion>4.0.0</modelversion> <groupid>de.nikostotz.xtendxcoremaven</groupid> <version>1.0.0-SNAPSHOT</version> <artifactid>de.nikostotz.xtendxcoremaven</artifactid> <properties> <project .build.sourceEncoding>UTF-8</project> <!-- Java version, will be honored by Xcore / Xtend --> <maven .compiler.source>1.8</maven> <maven .compiler.target>1.8</maven> <!-- Xtend / Xcore --> <core -resources-version>3.7.100</core> <eclipse -text-version>3.5.101</eclipse> <emf -version>2.12.0</emf> <emf -common-version>2.12.0</emf> <emf -codegen-version>2.11.0</emf> <xtext -version>2.10.0</xtext> <ecore -xtext-version>1.2.0</ecore> <ecore -xcore-version>1.3.1</ecore> <ecore -xcore-lib-version>1.1.100</ecore> <emf -mwe2-launch-version>2.8.3</emf> </properties> <dependencies> <dependency> <groupid>org.eclipse.emf</groupid> <artifactid>org.eclipse.emf.common</artifactid> <version>${emf-common-version}</version> </dependency> <dependency> <groupid>org.eclipse.emf</groupid> <artifactid>org.eclipse.emf.ecore</artifactid> <version>${emf-version}</version> </dependency> <dependency> <groupid>org.eclipse.emf</groupid> <artifactid>org.eclipse.emf.ecore.xcore.lib</artifactid> <version>${ecore-xcore-lib-version}</version> </dependency> <dependency> <groupid>org.eclipse.xtext</groupid> <artifactid>org.eclipse.xtext.xbase.lib</artifactid> <version>${xtext-version}</version> </dependency> </dependencies> <build> <plugins> <plugin> <groupid>org.apache.maven.plugins</groupid> <artifactid>maven-compiler-plugin</artifactid> <version>3.3</version> </plugin> <plugin> <artifactid>maven-clean-plugin</artifactid> <version>2.6.1</version> <configuration> <filesets> <fileset> <excludes> <exclude>.dummy.txt</exclude> </excludes> <directory>emf-gen</directory> </fileset> <fileset> <excludes> <exclude>.dummy.txt</exclude> </excludes> <directory>xtend-gen</directory> </fileset> <fileset> <excludes> <exclude>.dummy.txt</exclude> </excludes> <directory>xcore-gen</directory> </fileset> </filesets> </configuration> </plugin> <!-- Adds the generated sources to the compiler input --> <plugin> <groupid>org.codehaus.mojo</groupid> <artifactid>build-helper-maven-plugin</artifactid> <version>1.9.1</version> <executions> <execution> <id>add-source</id> <phase>generate-sources</phase> <goals> <goal>add-source</goal> </goals> <configuration> <!-- This should be in sync with xtext-maven-plugin//source-roots, except for /model directory --> <sources> <source />${basedir}/emf-gen <source />${basedir}/xcore-gen <source />${basedir}/xtend-gen </sources> </configuration> </execution> </executions> </plugin> <!-- Generates the Ecore model via MWE2 --> <plugin> <groupid>org.codehaus.mojo</groupid> <artifactid>exec-maven-plugin</artifactid> <version>1.4.0</version> <executions> <execution> <id>mwe2Launcher</id> <phase>generate-sources</phase> <goals> <goal>java</goal> </goals> </execution> </executions> <configuration> <mainclass>org.eclipse.emf.mwe2.launch.runtime.Mwe2Launcher</mainclass> <arguments> <argument>${project.basedir}/workflow/generateGenModel.mwe2</argument> <argument>-p</argument> <argument>rootPath=${project.basedir}/..</argument> </arguments> <classpathscope>compile</classpathscope> <includeplugindependencies>true</includeplugindependencies> <cleanupdaemonthreads>false</cleanupdaemonthreads><!-- see https://bugs.eclipse.org/bugs/show_bug.cgi?id=475098#c3 --> </configuration> <dependencies> <dependency> <groupid>org.eclipse.emf</groupid> <artifactid>org.eclipse.emf.mwe2.launch</artifactid> <version>${emf-mwe2-launch-version}</version> </dependency> <dependency> <groupid>org.eclipse.xtext</groupid> <artifactid>org.eclipse.xtext.xtext</artifactid> <version>${xtext-version}</version> </dependency> <dependency> <groupid>org.eclipse.text</groupid> <artifactid>org.eclipse.text</artifactid> <version>${eclipse-text-version}</version> </dependency> <dependency> <groupid>org.eclipse.core</groupid> <artifactid>org.eclipse.core.resources</artifactid> <version>${core-resources-version}</version> </dependency> <dependency> <groupid>org.eclipse.xtend</groupid> <artifactid>org.eclipse.xtend.core</artifactid> <version>${xtext-version}</version> </dependency> <dependency> <groupid>org.eclipse.xtext</groupid> <artifactid>org.eclipse.xtext.ecore</artifactid> <version>${xtext-version}</version> </dependency> <dependency> <groupid>org.eclipse.xtext</groupid> <artifactid>org.eclipse.xtext.xbase</artifactid> <version>${xtext-version}</version> </dependency> <dependency> <groupid>org.eclipse.emf</groupid> <artifactid>org.eclipse.emf.codegen.ecore.xtext</artifactid> <version>${ecore-xtext-version}</version> </dependency> <dependency> <groupid>org.eclipse.emf</groupid> <artifactid>org.eclipse.emf.common</artifactid> <version>${emf-common-version}</version> </dependency> <dependency> <groupid>org.eclipse.emf</groupid> <artifactid>org.eclipse.emf.ecore</artifactid> <version>${emf-version}</version> </dependency> <dependency> <groupid>org.eclipse.emf</groupid> <artifactid>org.eclipse.emf.ecore.xmi</artifactid> <version>${emf-version}</version> </dependency> <dependency> <groupid>org.eclipse.emf</groupid> <artifactid>org.eclipse.emf.codegen</artifactid> <version>${emf-codegen-version}</version> </dependency> <dependency> <groupid>org.eclipse.emf</groupid> <artifactid>org.eclipse.emf.codegen.ecore</artifactid> <version>${emf-codegen-version}</version> </dependency> <dependency> <groupid>org.eclipse.emf</groupid> <artifactid>org.eclipse.emf.ecore.xcore</artifactid> <version>${ecore-xcore-version}</version> </dependency> <dependency> <groupid>org.eclipse.emf</groupid> <artifactid>org.eclipse.emf.ecore.xcore.lib</artifactid> <version>${ecore-xcore-lib-version}</version> </dependency> <dependency> <groupid>org.eclipse.text</groupid> <artifactid>org.eclipse.text</artifactid> <version>${eclipse-text-version}</version> </dependency> <dependency> <groupid>org.eclipse.core</groupid> <artifactid>org.eclipse.core.resources</artifactid> <version>${core-resources-version}</version> </dependency> <dependency> <groupid>org.eclipse.xtend</groupid> <artifactid>org.eclipse.xtend.core</artifactid> <version>${xtext-version}</version> </dependency> <dependency> <groupid>org.eclipse.xtext</groupid> <artifactid>org.eclipse.xtext.ecore</artifactid> <version>${xtext-version}</version> </dependency> <dependency> <groupid>org.eclipse.xtext</groupid> <artifactid>org.eclipse.xtext.xbase</artifactid> <version>${xtext-version}</version> </dependency> <dependency> <groupid>org.eclipse.emf</groupid> <artifactid>org.eclipse.emf.codegen.ecore.xtext</artifactid> <version>${ecore-xtext-version}</version> </dependency> <dependency> <groupid>org.eclipse.emf</groupid> <artifactid>org.eclipse.emf.common</artifactid> <version>${emf-common-version}</version> </dependency> <dependency> <groupid>org.eclipse.emf</groupid> <artifactid>org.eclipse.emf.ecore</artifactid> <version>${emf-version}</version> </dependency> <dependency> <groupid>org.eclipse.emf</groupid> <artifactid>org.eclipse.emf.ecore.xmi</artifactid> <version>${emf-version}</version> </dependency> <dependency> <groupid>org.eclipse.emf</groupid> <artifactid>org.eclipse.emf.codegen</artifactid> <version>${emf-codegen-version}</version> </dependency> <dependency> <groupid>org.eclipse.emf</groupid> <artifactid>org.eclipse.emf.codegen.ecore</artifactid> <version>${emf-codegen-version}</version> </dependency> <dependency> <groupid>org.eclipse.emf</groupid> <artifactid>org.eclipse.emf.ecore.xcore</artifactid> <version>${ecore-xcore-version}</version> </dependency> <dependency> <groupid>org.eclipse.emf</groupid> <artifactid>org.eclipse.emf.ecore.xcore.lib</artifactid> <version>${ecore-xcore-lib-version}</version> </dependency> </dependencies> </plugin> <!-- Generates the Xtend and Xcore models --> <plugin> <groupid>org.eclipse.xtext</groupid> <artifactid>xtext-maven-plugin</artifactid> <version>${xtext-version}</version> <executions> <execution> <phase>generate-sources</phase> <goals> <goal>generate</goal> </goals> </execution> </executions> <configuration> <languages> <language> <setup>org.eclipse.xtext.ecore.EcoreSupport</setup> </language> <language> <setup>org.eclipse.emf.codegen.ecore.xtext.GenModelSupport</setup> </language> <language> <setup>org.eclipse.xtend.core.XtendStandaloneSetup</setup> <outputconfigurations> <outputconfiguration> <outputdirectory>${project.basedir}/xtend-gen</outputdirectory> </outputconfiguration> </outputconfigurations> </language> <language> <setup>org.eclipse.emf.ecore.xcore.XcoreStandaloneSetup</setup> <outputconfigurations> <outputconfiguration> <outputdirectory>${project.basedir}/xcore-gen</outputdirectory> </outputconfiguration> </outputconfigurations> </language> </languages> <!-- This should be in sync with build-helper-maven-plugin//sources, except for /model directory --> <sourceroots> <root>${basedir}/src</root> <root>${basedir}/emf-gen</root> <!-- Note that we include the /model path here although it's not part of the source directories in Eclipse or Maven --> <root>${basedir}/model</root> </sourceroots> <!-- This does not work currently, as we can see by the missing lambda in generated code for GreetingsHelper.compileAllGreetings(). It does work, however, for xtend-maven-plugin. (see https://github.com/eclipse/xtext-maven/issues/11)--> <javasourceversion>1.8</javasourceversion> </configuration> <dependencies> <dependency> <groupid>org.eclipse.text</groupid> <artifactid>org.eclipse.text</artifactid> <version>${eclipse-text-version}</version> </dependency> <dependency> <groupid>org.eclipse.core</groupid> <artifactid>org.eclipse.core.resources</artifactid> <version>${core-resources-version}</version> </dependency> <dependency> <groupid>org.eclipse.xtend</groupid> <artifactid>org.eclipse.xtend.core</artifactid> <version>${xtext-version}</version> </dependency> <dependency> <groupid>org.eclipse.xtext</groupid> <artifactid>org.eclipse.xtext.ecore</artifactid> <version>${xtext-version}</version> </dependency> <dependency> <groupid>org.eclipse.xtext</groupid> <artifactid>org.eclipse.xtext.xbase</artifactid> <version>${xtext-version}</version> </dependency> <dependency> <groupid>org.eclipse.emf</groupid> <artifactid>org.eclipse.emf.codegen.ecore.xtext</artifactid> <version>${ecore-xtext-version}</version> </dependency> <dependency> <groupid>org.eclipse.emf</groupid> <artifactid>org.eclipse.emf.common</artifactid> <version>${emf-common-version}</version> </dependency> <dependency> <groupid>org.eclipse.emf</groupid> <artifactid>org.eclipse.emf.ecore</artifactid> <version>${emf-version}</version> </dependency> <dependency> <groupid>org.eclipse.emf</groupid> <artifactid>org.eclipse.emf.ecore.xmi</artifactid> <version>${emf-version}</version> </dependency> <dependency> <groupid>org.eclipse.emf</groupid> <artifactid>org.eclipse.emf.codegen</artifactid> <version>${emf-codegen-version}</version> </dependency> <dependency> <groupid>org.eclipse.emf</groupid> <artifactid>org.eclipse.emf.codegen.ecore</artifactid> <version>${emf-codegen-version}</version> </dependency> <dependency> <groupid>org.eclipse.emf</groupid> <artifactid>org.eclipse.emf.ecore.xcore</artifactid> <version>${ecore-xcore-version}</version> </dependency> <dependency> <groupid>org.eclipse.emf</groupid> <artifactid>org.eclipse.emf.ecore.xcore.lib</artifactid> <version>${ecore-xcore-lib-version}</version> </dependency> </dependencies> </plugin> </plugins> </build> </project> |
.gitignore
1 2 3 4 5 | bin/* target emf-gen/* xcore-gen/* xtend-gen/* |
About the Author Niko Stotz
 I'm an IT geek with sound understanding of the business side. My field of interest is modeling technology and I love playing with (German) language. I work for F1re in Eindhoven. This blog represents my personal viewpoint.
I'm an IT geek with sound understanding of the business side. My field of interest is modeling technology and I love playing with (German) language. I work for F1re in Eindhoven. This blog represents my personal viewpoint.