tl;dr An interpreter framework prototype based on GraalVM / Truffle shows two orders of magnitude better performance than the previous implementation. Vote for Java Annotation Processor support in MPS to help this effort.
Overview
At the great MPS Meetup last week in Munich I had a chance to give a talk on the MPS Interpreter Framework I worked on at itemis. The slides are available, and the talk was recorded.
We had an enthusiastic audience with lots of questions. This skewed my timing a bit, thus I could only spend a few minutes on my latest experiments in this field: A new take on the interpreter framework, based on GraalVM / Truffle. Meinte Boersma inspired this blog post to add more details — thanks a lot for the motivation, Meinte!
To shortly recap the first part of my talk: Interpreters are easy to implement, especially if an MPS language avoids the usual boilerplate and integration in the typesystem gets rid of instanceof and casting orgies. This is pretty much the the state of the existing Interpreter Framework, which is used in a lot of real-world projects (e.g. KernelF or at the Dutch tax office).
This leaves us with one big drawback of interpreters: Usually, their performance is pretty bad. Enter GraalVM!
GraalVM is a highly optimized just-in-time-compiler for Java. It also provides an API to the code running on the JVM, and thus can be leveraged by Truffle.
Truffle is a library to implement high-performance interpreters, it uses all the tricks in the book: AST rewriting, partial evaluation, polymorphic inline caches, …, you name it. This leads to pretty impressive performance, like 90 % of the hand-optimized V8 JavaScript engine. Truffle makes use of GraalVM, but also runs on a regular JVM.
Another part of GraalVM ecosystem is called Polyglot. It allows interaction and optimization across languages, e.g. starting a JavaScript program, calling an R routine, which calls Ruby, which uses JavaScript, and all of this without data serialization or performance drawback.
Incidentally, Oracle released GraalVM 1.0 this week. We might see a lot more traction in this field.
Based on the first non-representative, non-exhaustive tests, GraalVM delivers big time:
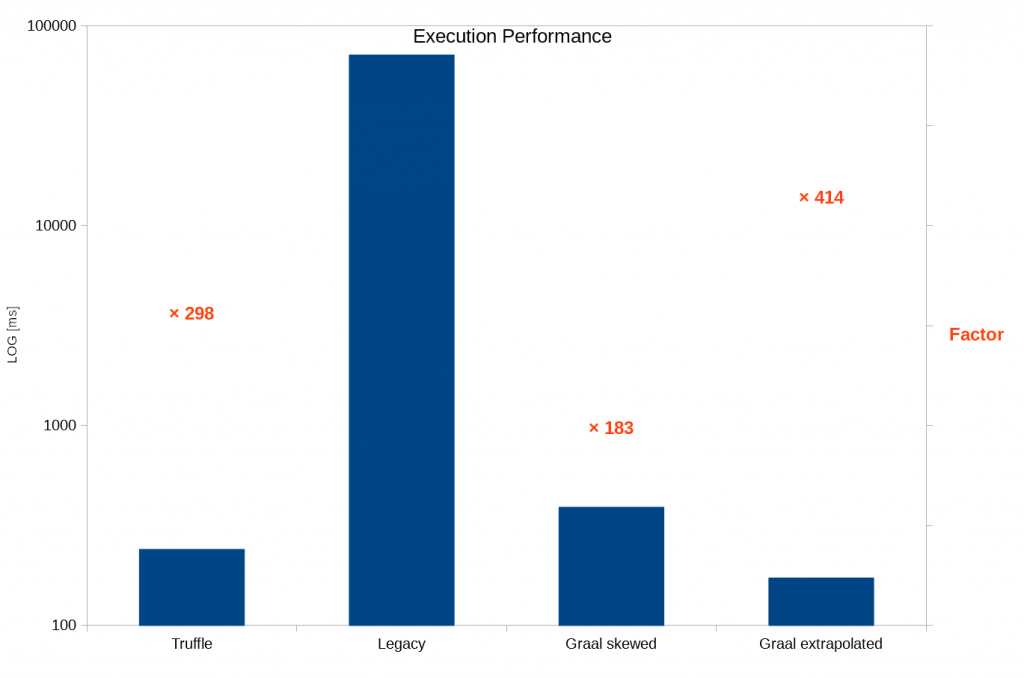
- Truffle runs within MPS, but on a regular JVM (i.e. without GraalVM JIT).
- Legacy is the existing interpreter framework within MPS.
- Graal skewed runs Truffle within MPS on a GraalVM JIT. I must have messed up something there, as the performance should be better than pure Truffle. Also, MPS itself felt quite sluggish with this configuration.
- Graal extrapolated uses the stand-alone version (outside MPS) as a comparison what should be achievable.
Please note that the test program was quite basic, probably leading to overly optimistic results. However, I used a pretty old version of GraalVM (shipped with JDK9 on Windows) and Truffle (0.30), and reportedly newer versions perform a lot better. So in total, I think we can expect two orders of magnitude better performance.
Technical Details
GraalVM
GraalVM is available in a special build of Java8 on Linux and Mac. Java9 on Windows and Mac and Java10 on Linux also contain a (probably outdated) version of GraalVM.
As my current development environment is on Windows, I first tried to build the source version of GraalVM on Windows. I finally got it built, but the resulting java.exe segfaulted even on java.exe -version.
The next best way was to get MPS running on Java9. If we’re using Java8 for compilation and Java9 only as a runtime environment, we only need a few adjustments to the MPS sources. I put my hack on github. Be warned: it contains a few hard-coded local paths!
Truffle
Truffle relies on Java Annotation Processors, a standardized way to extend the Java compiler.
MPS internally uses the Eclipse java compiler, which fully supports annotation processors. The Eclipse java compiler also supports both the IntelliJ compiler infrastructure and the Java standard for calling compilers, but MPS uses a hand-knitted interface to the compiler without annotation processor support. I opened a Feature request for MPS to support Annotation Processors, so please upvote if you’re interested in high-performance interpreters.
My aforementioned hack also contains changes to enable the required annotation processors within MPS.
TruffleInterpreter Language
I started the language from scratch for several reasons:
- The existing Interpreter language was the first thing I implemented in MPS, and I learned a lot since then.
- The interpreter should become its own language aspect, thus requiring considerable changes anyway.
- Understanding Truffle and generating the correct code for it is hard enough, I didn’t want to add the burden of non-fitting abstractions.
- We need quite some additional information for the new backend.
Obviously, I kept the nice parts regarding concise syntax and typesystem integration.
I did not spend much time yet on beautifying the language, but I think the general idea is already recognizable.
As a playground, I implemented SimpleLanguage as shipped with Truffle in both MPS interpreter frameworks. (Please find screenshots of the complete interpreters at the end of this post.)
Let’s look at a few examples from both interpreters:
-
Invoke Expression
Invoke maps quite directly.Legacy

Truffle

-
Plus Expression
Plus is also similar, but we can spot some differences:- Mixtures of types are handled automatically by Truffle
- Truffle adds programmatic type guards for the String overload
Legacy

Truffle

-
Typemapping
The actual typemapping is very similar. However, Truffle needs to know about the run-time (aka interpretation-time) typesystem including type checks, type casts, and implicit casts.Legacy

Truffle

The Truffle variant contains a few more hints only accessible via inspector.
I guess a converter from legacy to Truffle interpreters should be feasible, but the result might not run out-of-the-box.
Implementation
The implementation faced three main issues:
-
Generating the correct code for Truffle
Truffle is very picky about what code it accepts, e.g. some fields must be final, but others must not. There seems no way for annotation processors to emit messages during compilation. Thus, we generate some code, and it either works or not, without any hints (in some cases we pass the compilation steps and get hints during execution).
-
Providing the generated truffle interpreter to the Truffle runtime
Truffle expects all its languages to be available in its classpath at startup.
So currently, we cannot change the interpreters after the first invocation of any (!) interpreter.
There might be a way to add languages at runtime, but my hunch is this would get us into never-ending classloading issues. See below for thoughts on a better approach. -
Running annotation processors the same time as the regular compilation
The code generated by MPS contains calls to classes only generated by Truffle’s annotation processors, so we have to execute both in the same step.
Re-implementing Truffle’s generators in MPS is also not an option, both from their size and complexity.This picture compares the input MPS Concepts mentioned in the interpreter, Java source files generated by MPS, and produced Java classes

A small snippet of the Truffle-generated code. Who wants to tell me where I took it from?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41private Object executeGeneric_generic1(VirtualFrame frameValue, int state) {
Object leftValue_ = this.left_.executeGeneric(frameValue);
Object rightValue_ = this.right_.executeGeneric(frameValue);
if ((state & 2) != 0 && leftValue_ instanceof Long) {
long leftValue__ = (Long)leftValue_;
if (rightValue_ instanceof Long) {
long rightValue__ = (Long)rightValue_;
try {
return this.specialization(leftValue__, rightValue__);
} catch (ArithmeticException var14) {
Lock lock = this.getLock();
lock.lock();
try {
this.exclude_ |= 1;
this.state_ &= -3;
} finally {
lock.unlock();
}
return this.executeAndSpecialize(leftValue__, rightValue__);
}
}
}
if ((state & 4) != 0 && SLxTypesGen.isImplicitBigInteger((state & 48) >>> 4, leftValue_)) {
BigInteger leftValue__ = SLxTypesGen.asImplicitBigInteger((state & 48) >>> 4, leftValue_);
if (SLxTypesGen.isImplicitBigInteger((state & 192) >>> 6, rightValue_)) {
BigInteger rightValue__ = SLxTypesGen.asImplicitBigInteger((state & 192) >>> 6, rightValue_);
return this.specialization(leftValue__, rightValue__);
}
}
if ((state & 8) != 0 && this.guardSpecialization(rightValue_, leftValue_)) {
return this.specialization(leftValue_, rightValue_);
} else {
CompilerDirectives.transferToInterpreterAndInvalidate();
return this.executeAndSpecialize(leftValue_, rightValue_);
}
}
Lifecycle

- We start by defining our Language SimpleLanguage as usual. As an example, we define a concept SlPlus.
- We create a TruffleInterpreter for SimpleLanguage. In the interpreter, we create the evaluator for SlPlus.
- The generator of TruffleInterpreter turns the evaluator for SlPlus into a Java class named SlPlusNode that inherits from TruffleNode.
- Once we want to evaluate our instance model of SimpleLanguage, the TruffleInterpreter framework converts all instances of SlPlus (i.e. MPS nodes of concept SlPlus) into instances of SlPlusNode (i.e. Java objects of class SlPlusNode).
- The TruffleInterpreter framework invokes the TruffleRuntime on the recently created SlPlusNode object.
- We can retrieve the result of our interpretation, e.g. a java.lang.Long object, from TruffleRuntime.
Truffle requires all evaluated nodes to be TruffleNodes to do its magic.
This implies some overhead to convert MpsNodes into TruffleNodes, but allows us to execute the interpreter without model access afterwards. We can even run the interpreter in a different thread and update our editor once the calculation is done.
Language Interoperability
The Polyglot part of GraalVM allows arbitrary mixture of languages. The prototype contains an example to call JavaScript:

(You have to know this joke!)
Polyglot supports language interoperability with complex types, but I didn’t implement this yet in this prototype.
Future Work
Turn Prototype into Production Code
This blog post is about a prototype, meant to explore the possibilities, pitfalls and benefits. It breaks quickly if you try something different. It does not implement all features of Truffle. The generator does not need to be rewritten from scratch, but needs a serious overhaul. The language is too close to Truffle specifics, and thus hard to use if you don’t know about Truffle.
Interpreter Language Aspect
Interpreters should be a separate language aspect, the same way as typesystem or constraints. At the MPS Meetup we agreed that executing your models is highly valuable in lots of domains; a language aspect emphasizes this importance.
Also, having a language aspect should improve integration with the rest of the MPS ecosystem and ease classloading for interpreters.
One Interpreter for all Languages
The current implementation registers every interpreter as its own Truffle language; the idea was to leverage Polyglot for language interaction. However, this leads to classloading issues.
An alternative would be to look at interpreters similar to editors: In MPS, we have a standard editor for all concepts. If we need to, we can provide other editors triggered by editor hints. Similarly, we could have one standard language (from a Truffle point of view), and all interpreters contribute to this standard Truffle language. We might register a few secondary Truffle languages by default, so we don’t have to restart MPS as soon as anybody wants to use an “interpreter hint”.
This should maintain MPS language extensibility, as any MPS language can contribute standard interpreters for any concept, or might register secondary interpreters with an “interpreter hint”.
I’m not sure yet what to do about nodes without any known interpreter. We might want to ignore them, or traverse their subnodes to find something we can interpret.
Fine-tuning MpsNode → TruffleNode Conversion
The current implementation converts an arbitrary selection of MpsNodes into TruffleNodes prior to invoking the interpreter. We could think of other approaches:
- Convert the starting node and all contained and related nodes up to a specific depth; At the end of each branch, we’d insert a “ReloadNode” to convert more nodes once it’s needed.
- We could keep the converted TruffleNodes in memory and update them on any changes to the underlying MpsNodes (aka “Shadow model”).
- It should be feasible to make our TruffleNodes serializable. Thus, we could save and reload them on MPS restart, or even execute them outside MPS.
Typesystem Integration
As mentioned above, the Truffle interpreter needs to know a lot about runtime types. At least for some of the information, we might be able to infer it from the MPS typesystem aspect.
Scoping Integration
If our interpreted language had nested scopes, maybe even including shadowing, the interpreter needs to know this. We might be able to infer this knowledge from the MPS constraints aspect.
DSL for Objects
Polyglot supports direct interaction between different languages on complex types. I only scratched this topic yet, but so far this seems to be very exiting both to interact with non-MPS Truffle languages (GraalVM ships with implementations of JavaScript, R, and Ruby) and to enable language composition at runtime.
Truffle bases the interaction on a concept called Shapes; I’m pretty sure there could be a DSL to ease their usage.
Debugger Integration
For smaller interpreted programs, something similar to the Trace Explorer available for the legacy Interpreter could be very useful.
GraalVM supports exposing the interpreted program via the standard JVM debugging APIs, including breakpoints and introspection. Contrary to popular belief, a Java program can debug itself, as long as the debugger and the target (i.e. interpreter) run in different threads. So we might be able to use the debugging UI included in MPS (as inherited from IntelliJ) to debug our interpreted program. A long time ago, I wrote a proof-of-concept of this idea for the legacy Interpreter, so we know we can get to the appropriate APIs.
Ahead-of-Time Compilation Support
A yet unmentioned part of GraalVM is called Sulong: An ahead-of-time-compiler for Truffle languages. I have no experience with Sulong, so I can only guess about its possibilities.
Especially in combination with serializable TruffleNodes this might lead to production-ready performance outside of MPS, thus rendering a separate implementation of the same logic in a generator obsolete.
Edit: I mixed up Sulong and SubstrateVM, as Oleg points out in the comments.
Appendix: Complete Interpreters
Legacy

Truffle

 I'm an IT geek with sound understanding of the business side. My field of interest is modeling technology and I love playing with (German) language. I work for
I'm an IT geek with sound understanding of the business side. My field of interest is modeling technology and I love playing with (German) language. I work for
Pingback: MPS’ Quest of the Holy GraalVM of Interpreters – Wriggling Through Features